このブログの前編は次のリンクで拝見できます:KNIMEを用いてのCGBVS計算を行います(前編)。
今回は、KNIME上でCGBVSワークフローとその実行の話をさせていただきます。作業ステップは以下のように分けています。
- KNIMEの起動と空きワークフローの作成
- 入力化合物構造の読み込み設定
- 化合物構造の記述子算出
- CGBVS計算の設定
- CGBVS計算結果のデータFiltering
- CGBVS計算結果をファイルに書き込むまたグラフ作成
それでは、早速始めましょう。
1.KNIMEの起動と空きワークフローの作成
まずは、KNIMEのアイコンをクリックするなどをして、以下の画像のようにKNIMEが起動されます。
新しいワークフロー作成するには、メニューの「File」→「New」をクリックします。
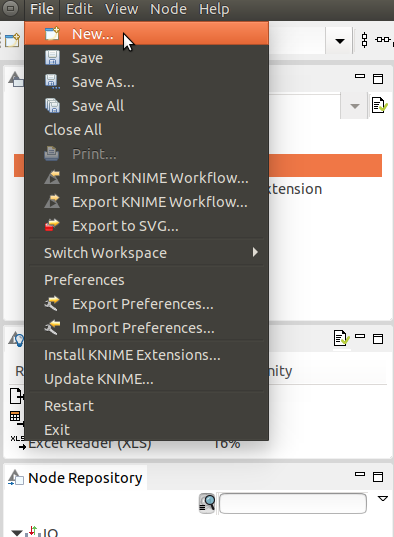
出てきたダイアログーボックスで「New KNIME workflow」を選択して「Next」ボタンをクリックします。
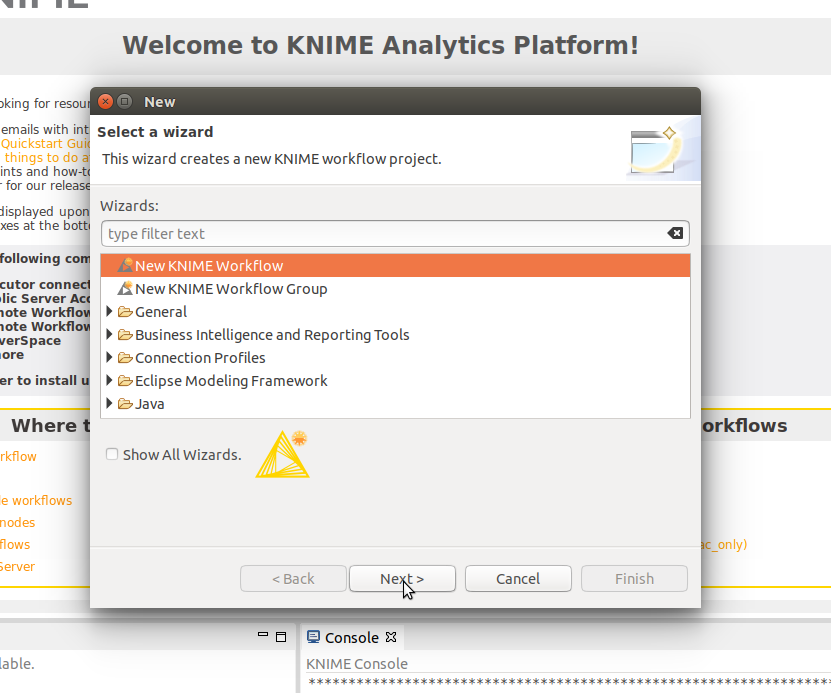
次のダイアログボックスでワークフローの名前とその保存場所を指定して「Finish」をクリックします。
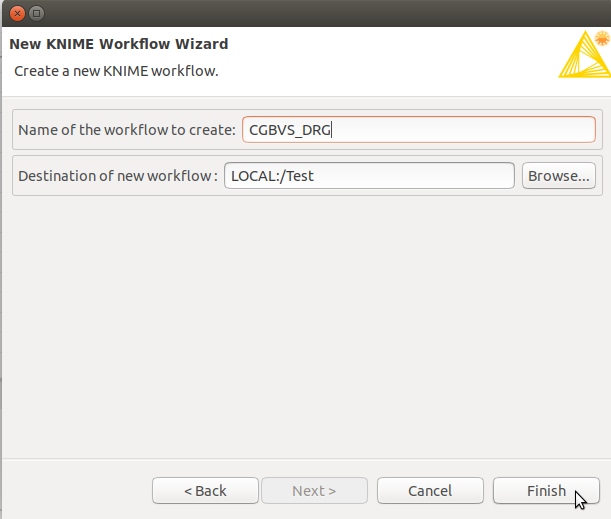
以下のように新しいワークフローの空きウィンドウが開かれます。
2.入力化合物構造の読み込み設定
SDF入力ファイルを読み込むため、以下のNode Repositoryで「SDF Reader」と言うnodeをクリックしてワークフローウィンドウまでドラッグします。新しく設置したnodeはまだ設定が出来ていないためビックリマークが出ています。また、nodeの下に赤信号のようなマークも出ています。
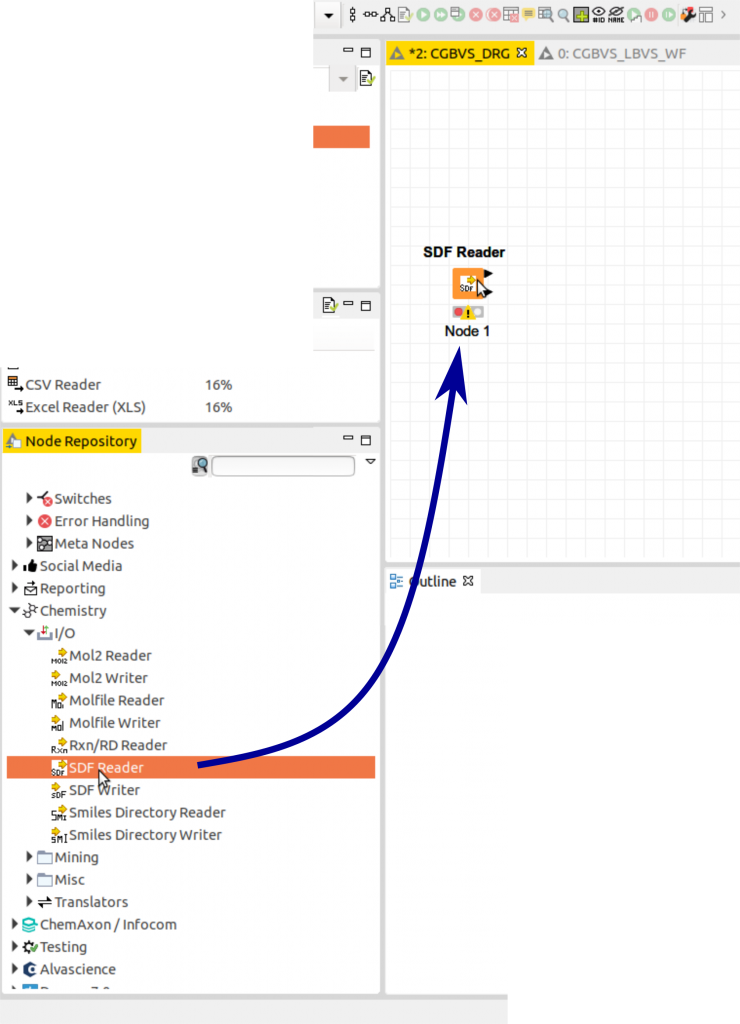
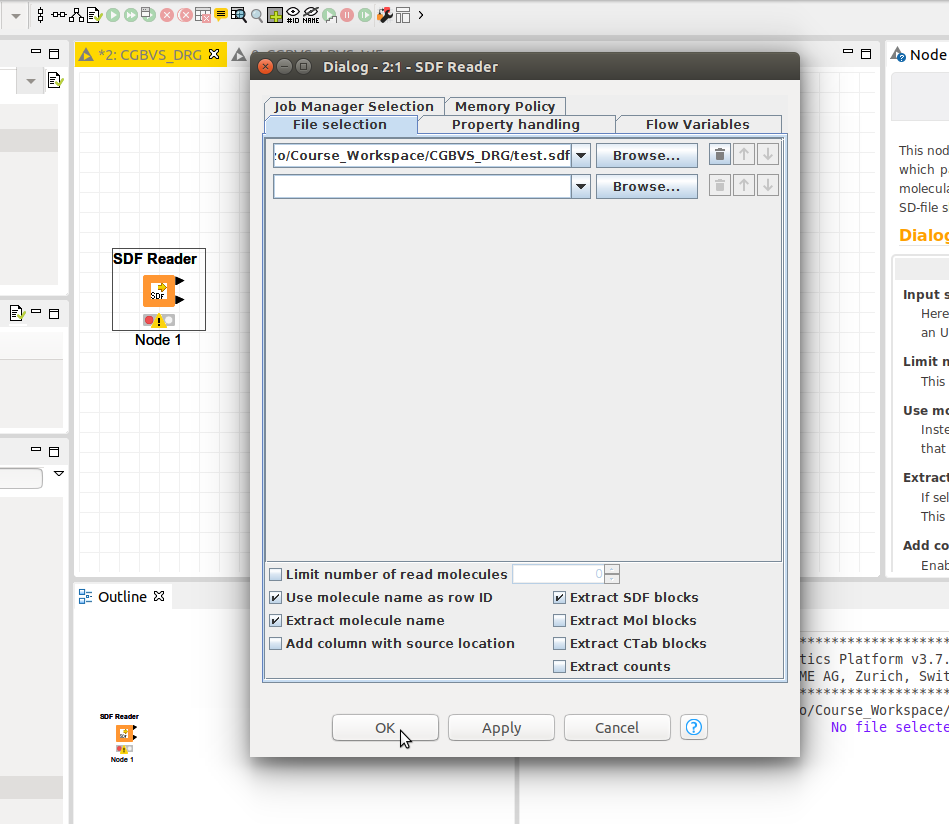
SDF Reader nodeをダブルクリックして設定ウィンドウが開きます。以下の画像のように入力ファイルの場所などを設定して「OK」をクリックします。「Extract SDF Blocks」の項目は構造情報を取り出すことですので、必ずクリックしてください。
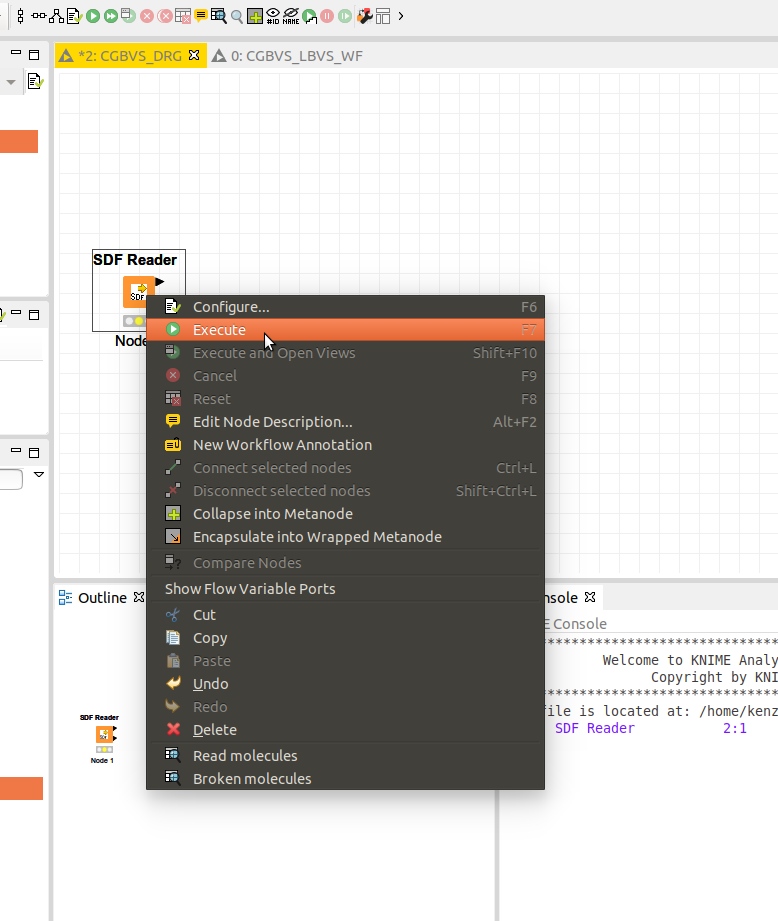
設定は問題なければ、赤信号のマークは黄色信号に変わります。実際にファイルを読み込むにはnodeを右クリックしてコンテキストメニューで「Execute」をクリックします。Nodeは問題なく動作した場合、黄色信号は緑(青?)信号に変わります。
3.化合物構造の記述子算出
次のステップはSDFからDragon記述子を作成する計算です。SDF Reader nodeのようにNode Repositoryから「Dragon 7.0 Descriptors」 nodeをワークフローウィンドウまでクリックドラッグします。
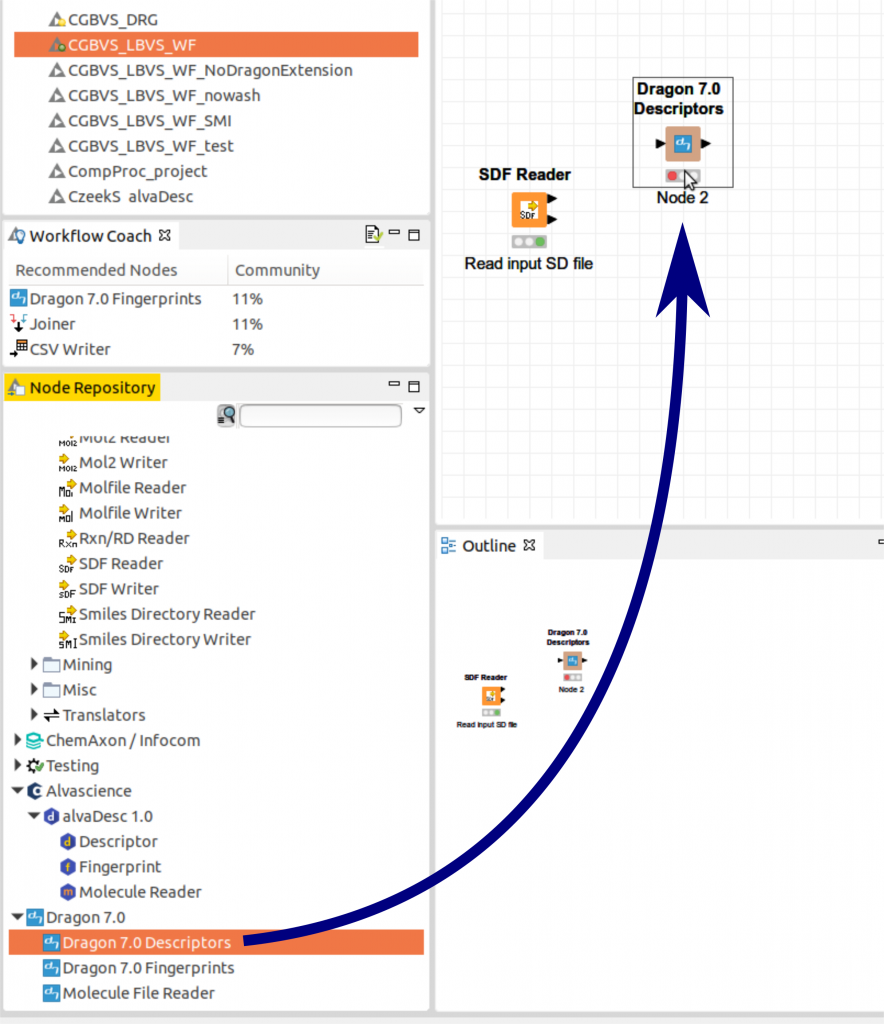
SDF Reader nodeの出力ポート(nodeの右側の上の三角)をDragon7の入力ポート(Dragon7 nodeの左側の三角)に繋ぎます。繋ぎ方としては、SDF Reader nodeの出力ポートからDragon7 nodeの入力ポートまでクリックドラッグします。以下の動画を参考にしてください。
Nodeを線で繋いだことでSDF reader nodeの出力データは直接Dragon7 nodeの入力ポートに入り、処理されます。次はその処理の設定を行いますのでDragon7 nodeをダブルクリックします。開いたダイアログボックスで以下の図のように最初の設定を行います。
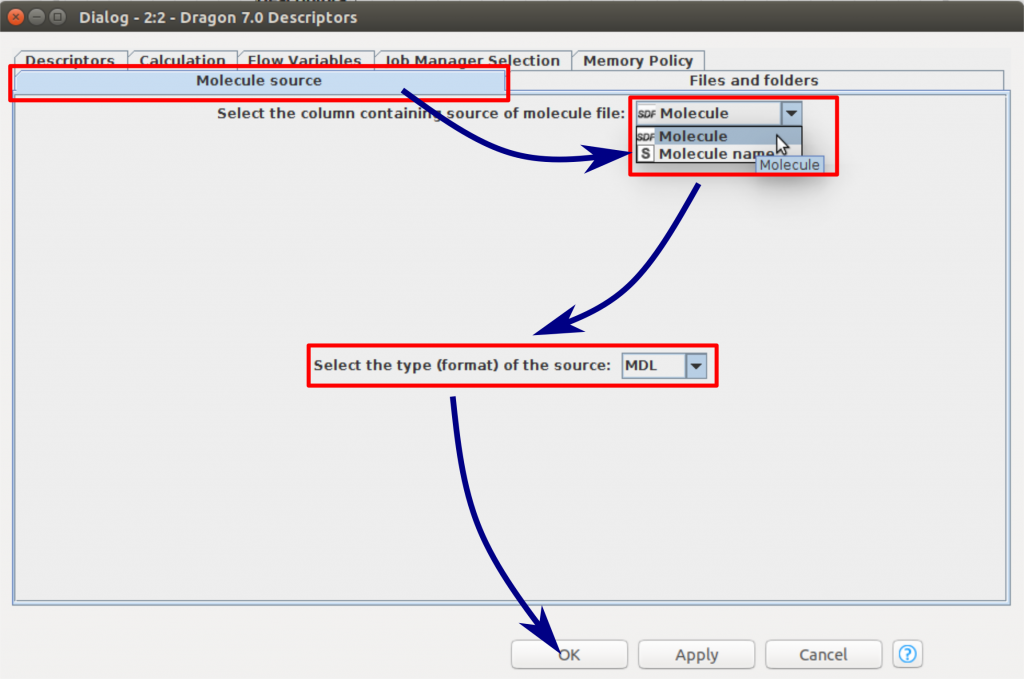
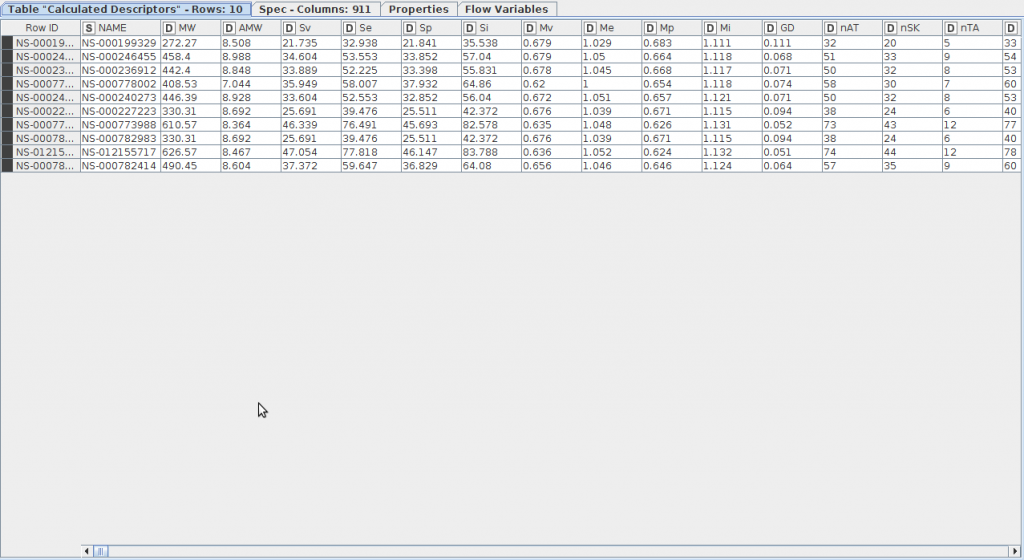
計算できる記述子が多くありますが、CGBVS計算で使用する記述子ブロックのみ選択します。「Descriptors」のタブをクリックしてから「Deselect all blocks」のボタンをクリックします。全部のブロックから「✓」を外した後、ブロック1、2、4、5、8、10、11,22、23、24、28を選択します。
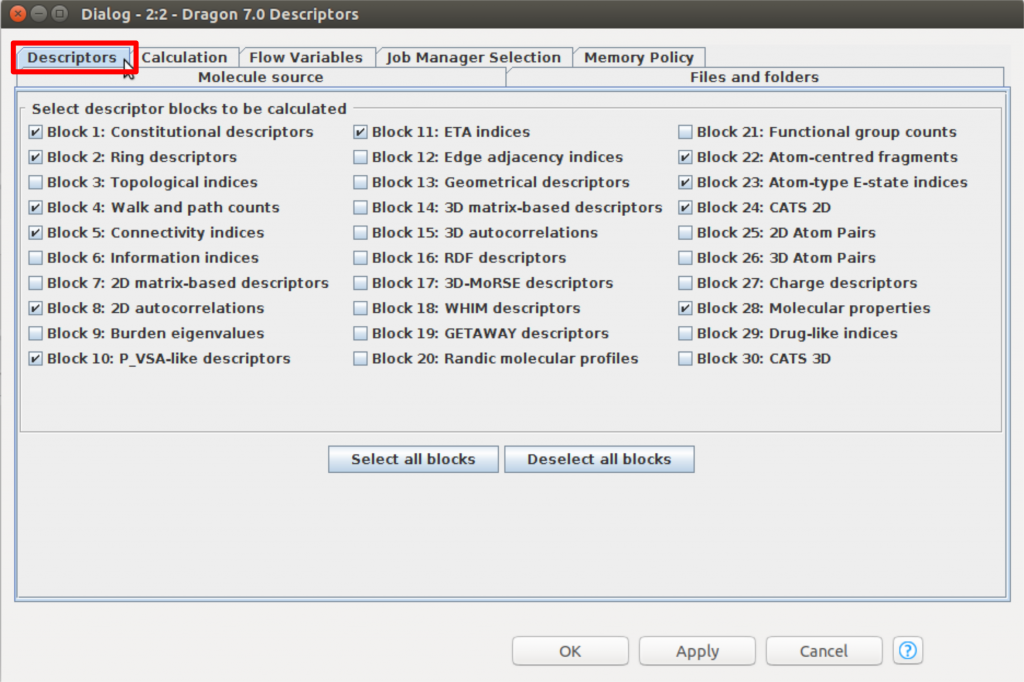
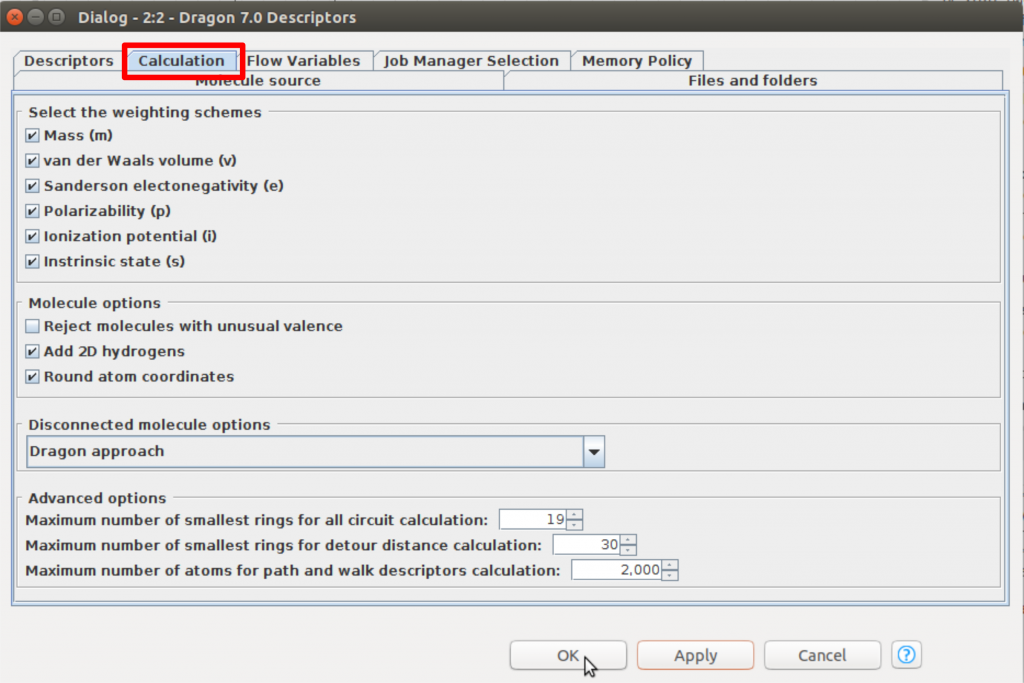
記述子計算の条件を設定する必要がありますので、「Calculation」のタブをクリックして、以下の図のように設定を行います。
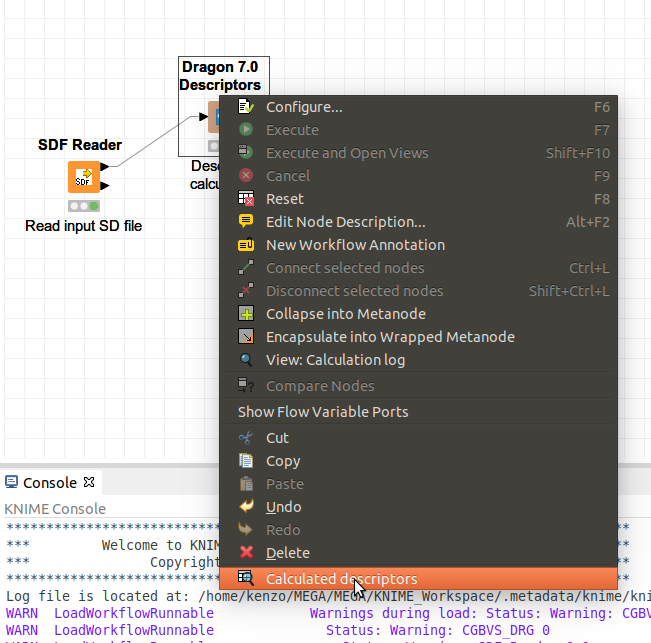
設定が終わったら、Dragon7 nodeを実行させます。信号マークが緑色に変わったら、計算処理の結果が確認できます。Dragon7 nodeを右クリックして、コンテキストメニューの一番したにある「Calculated descriptors」の項目をクリックします。出てきた、ポップアップウィンドウでは計算の結果が表示されます。確認が終わったらウィンドウを閉じます。
4.CGBVS計算の設定
前のステップでは、化合物の記述子を計算することができましたが、こちらではCGBVS計算を行います。CGBVSの専用nodeはありませんので、その代わりに「External Tool (Labs)」nodeを使用します。
External Tool (Labs) nodeをワークフローウィンドウにドラッグしてDragon7 nodeと繋ぎます。
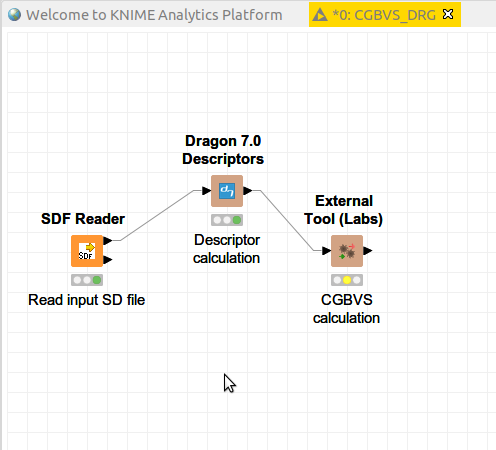
External Tool (Labs) nodeでCGBVS計算ができるように必要な設定を行います。開いた設定ウィンドウでは「External Tool」タブをクリックして、「Command line」のボックスに以下のようなコードを記入します。
bin/bash -c "/full/path/to/cgbvs predict /full/path/to/prediction/model/std_trans.db SC5A2_HUMAN %inFile% > %outFile%"上記のコードはパースの設定が自分のシステムに合うように内容を変えてください。以下はのコードの説明となります。
- cgbvs → cgbvsの実行ファイルです
- predict → cgbvsスコアを計算するサブコマンドです
- std_trans.db → Transporterを対象するモデルDBです(実際にはGPCR、Kinaseなどの他のDBファイルもあります)
- SCA5_HUMAN → 今回のため設定しましたタンパク名です
- %inFile% → 入力ファイルのプレースホルダーです
- %outFile% → 出力ファイルのプレースホルダーです
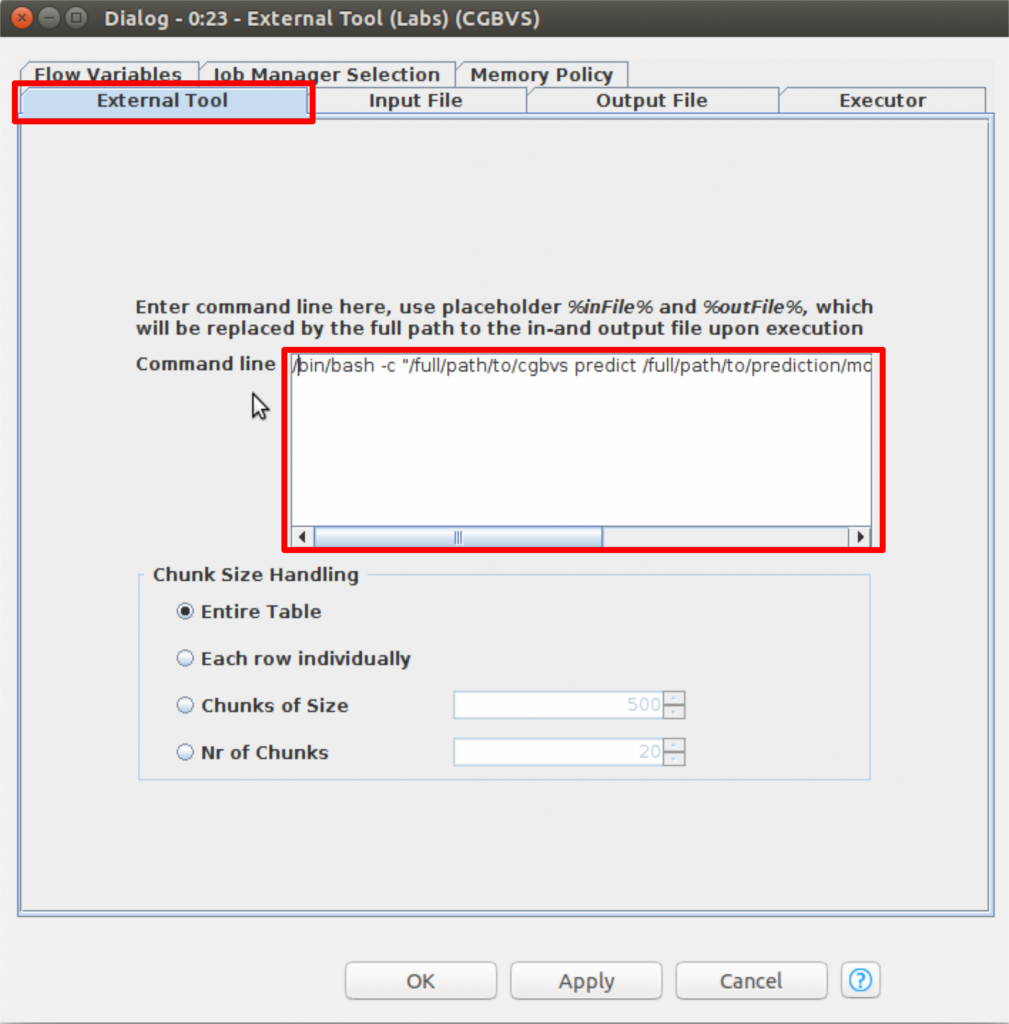
次は、「Input File」のタブをクリックして入力ファイルについて設定を行います。以下の図のように、「Exclude」のボックスに「Name」項目のみ移動します。他のパラメターも表示どおり設定してください。
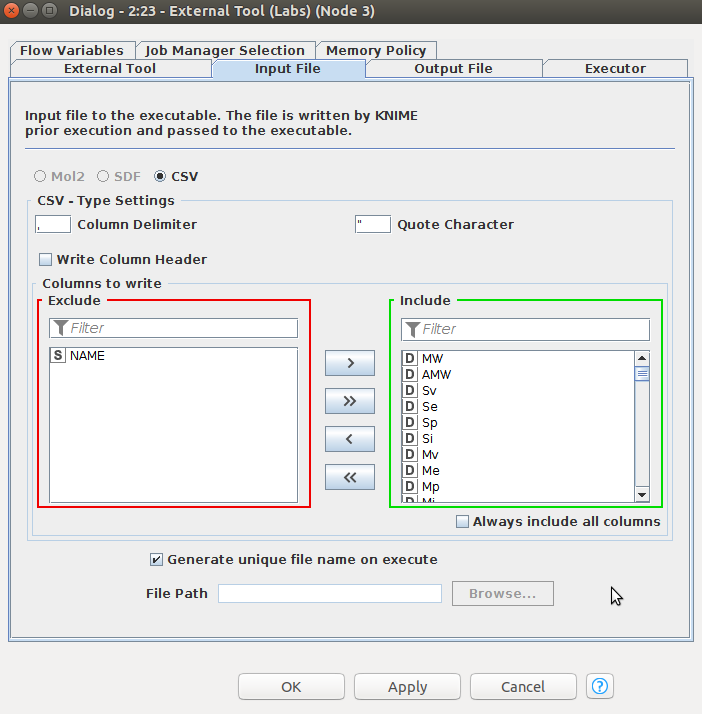
「Output File」の設定では、以下のような設定ですが、必ずCSVのボタンをクリックしてください。設定が完成しましたら「OK」ボタンをクリックしてください。
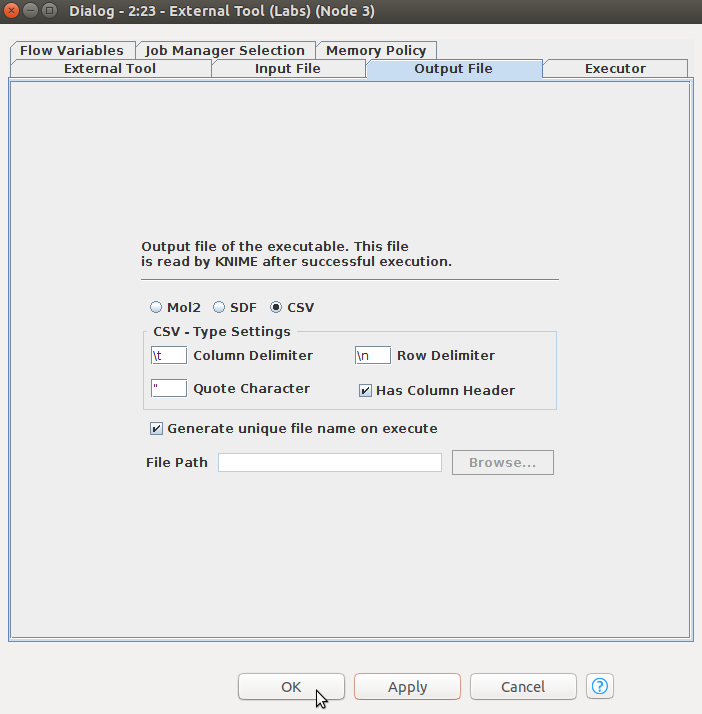
いつもの方法でnodeを実行してください。問題なければ、次のステップに進みます。
5.CGBVS計算結果のデータFiltering
前のステップで、CGBVSの計算を行いましたが、結果データには要らない部分が含まれているため、Filteringが必要となります。「Colum Filter」 nodeを使うことで要らないデータを省き化合物IDとCGBVSスコアのみ残すことが出来ます。
Node repositoryからColumn Filter nodeをワークフローウィンドウまでドラッグし、External Tool nodeに繋ぎます。
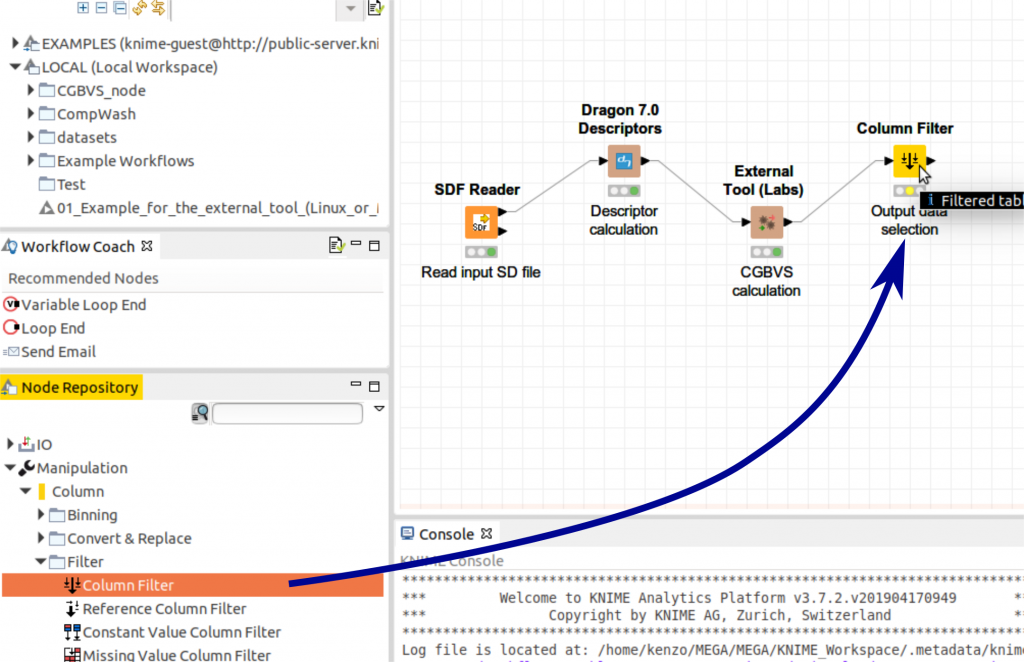
Nodeをダブルクリックして設定ウィンドウが開きます。「Include」ボックスのなかに「NAME」とタンパクの名前のみ入れます。この例では、タンパクの名前は「SC5A2_HUMAN」になっています。「OK」ボタンをクリックしてください。その後、nodeを実行させます。
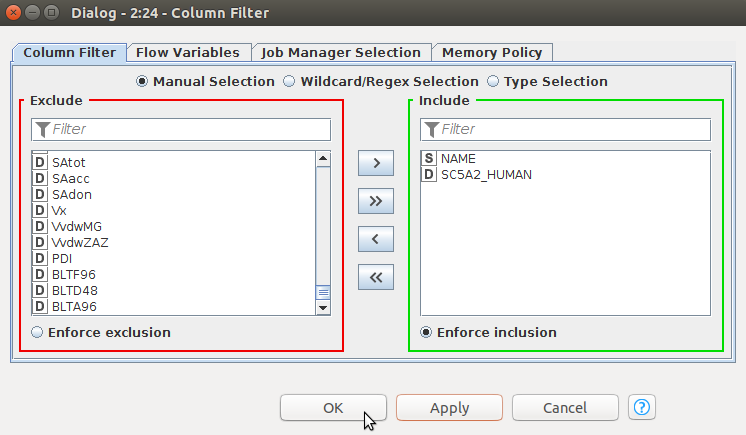
nodeのコンテキストメニューで「Filtered table」を選択してFilteringの結果を確認します。
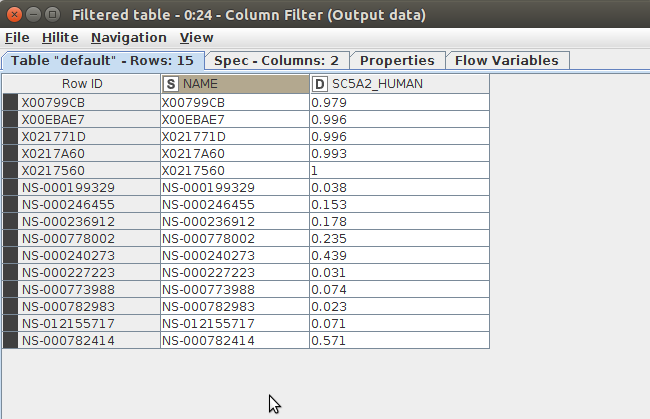
6.CGBVS計算結果をファイルに書き込むまたグラフ作成
ここのステップはCGBVS計算の結果ファイルに保存するために行います。このファイルは別のワークフローで使うことができます。ここでは、データをファイルに保存するするステップだけではなく、並行で、例えば、データからグラフを作成することもできます。
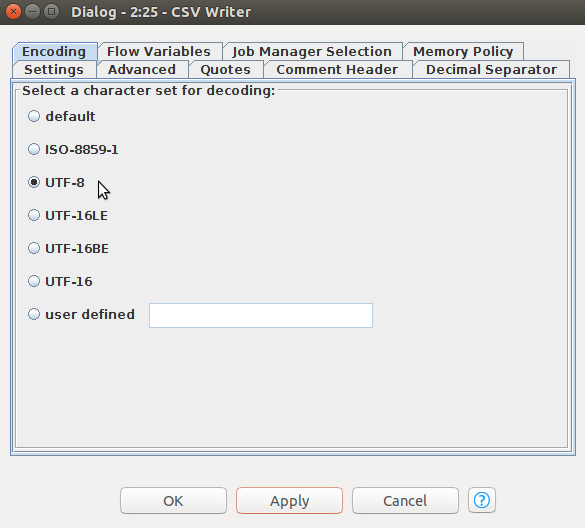
先ず、「CSV Writer」 nodeをワークフローウィンドウにドラッグしてColumn Filter nodeと繋ぎます。CSV Writer nodeをダブルクリックして設定を行います。最初に開くタブ、「Settings」では結果ファイルを保存するパースを指定します。また、「Write column header」のチェックボックスにチェックを入れます
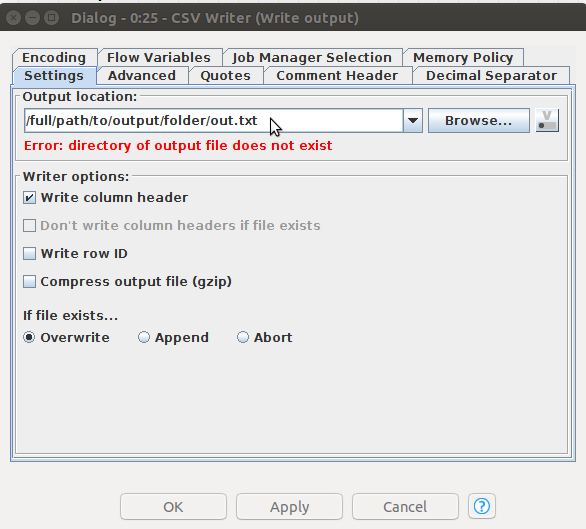
「Advanced」タブでは、「LF line endings (Linux/Unix style)」をクリックします。
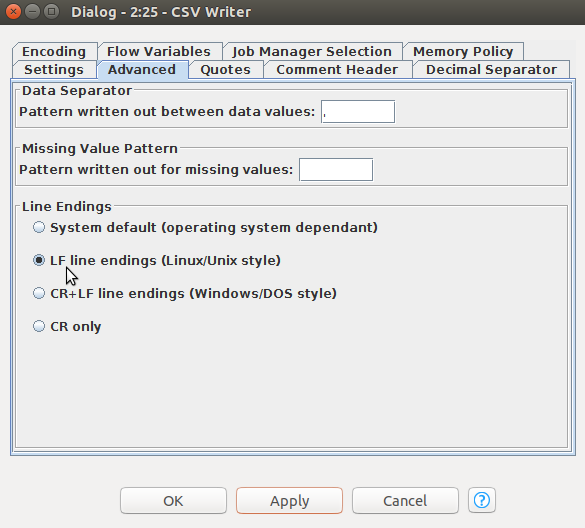
「Quotes」タブでは「Quote Mode」の枠で「never」をクリックします
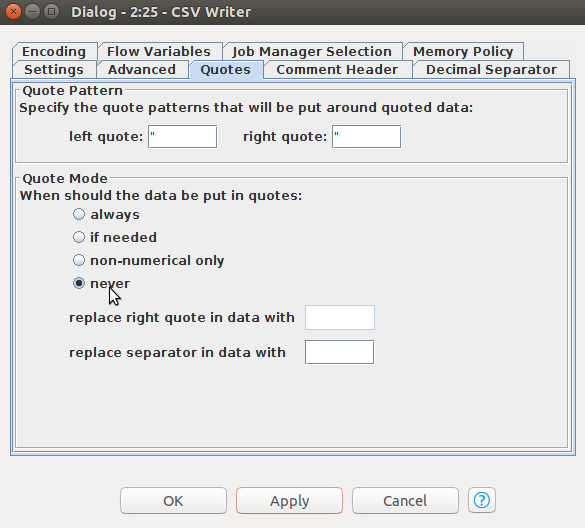
最後に、「Encoding」タブで「UTF-8」を選択します。「OK」ボタンをクリックします。
CSV writer nodeを実行して、保存ファイルの中身を確認します。
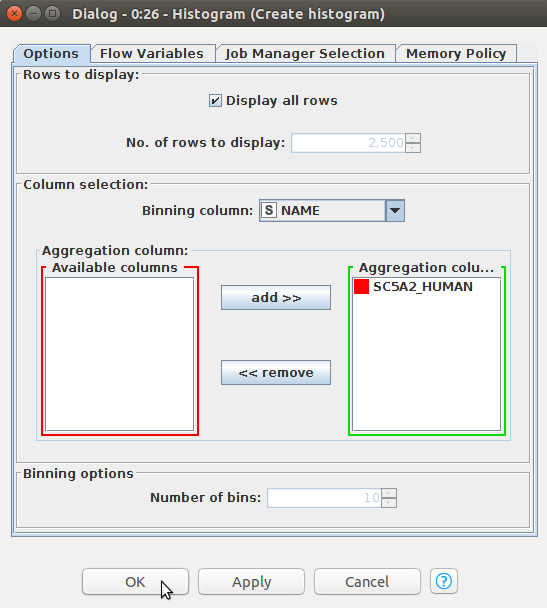
先に述べたように、計算結果のデータからグラフを作成することができます。そのためには「Histogram」nodeを使います。そのnodeを設置して、「Column Filter」nodeに繋ぎます。Histogram nodeの設定ウィンドウは以下になりますが、今回のデータの場合はdefaultの設定のままで使います。
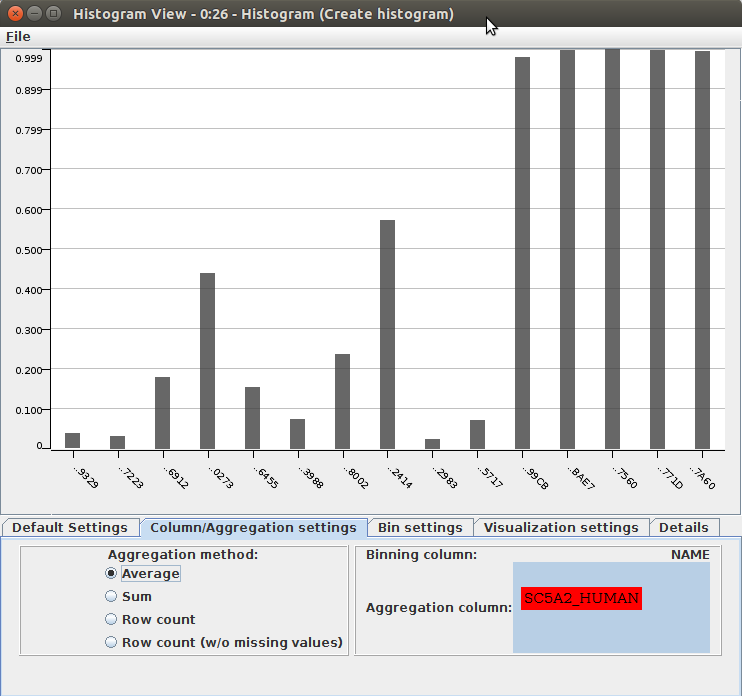
Nodeを実行し、コンテキストメニューで「View: Histogram view」を選択してグラフを表示します。Histogram viewでは「Column/Aggregation Settings」タブで「Average」をクリックすればそれぞれの化合物のCGBVSスコアを比較できます。基本的にCGBVSのスコアは0~1の値になります。0.5以上のスコアはpositive結果として判定されます。
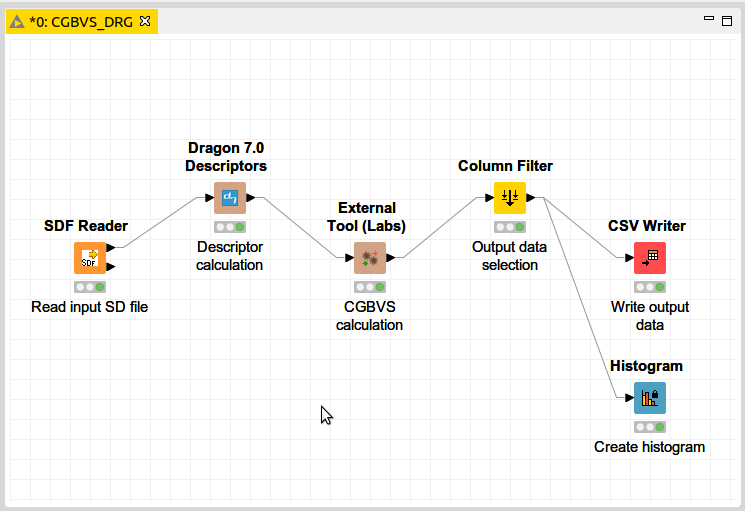
完成しましたワークフローは以下になります。一つの豆知識ですが、ワークフローのなかで少なくても1個のnodeの設定を変更したら、全体を再実行する必要がありますが、一番最後のnodeだけ実行すれば他のnodeも自動的に実行されます。ただし、並列に繋がっているnodeがあれば、それだけのnodeを個別に実行する必要があります。例えば、以下の図でCSV WriterとHistogram nodeを別々で実行する必要があります。
これでKNIMEを使用するCGBVS計算のワークフローが完成です。
最後までお読み頂きありがとうございます。
Category: CGBVS/CzeekS, DRAGON/alvaDesc